前言
近日得到一任务:需要爬取某个公众号的文章并保存到本地,然后进行分析。那么对于公众号爬取确实是比较少见而且有点难度,在搜集资料后,结合网络文章的经验以及自己的改进,实现了这一功能。参考文章会在文末列出。
准备
- Python环境
- 电脑或是服务器
- 一个自己能登陆的微信公众号
批量获取公众号推送链接
由于公众号的每一篇文章的链接似乎是随机生成的,相互之间没有关联,因此要批量获取某公众号的文章链接需要用到一定的方法,搜狗微信只能获取到最近的几篇文章,并不能做到全部收录。这里就需要用到自己的微信公众号的后台了。
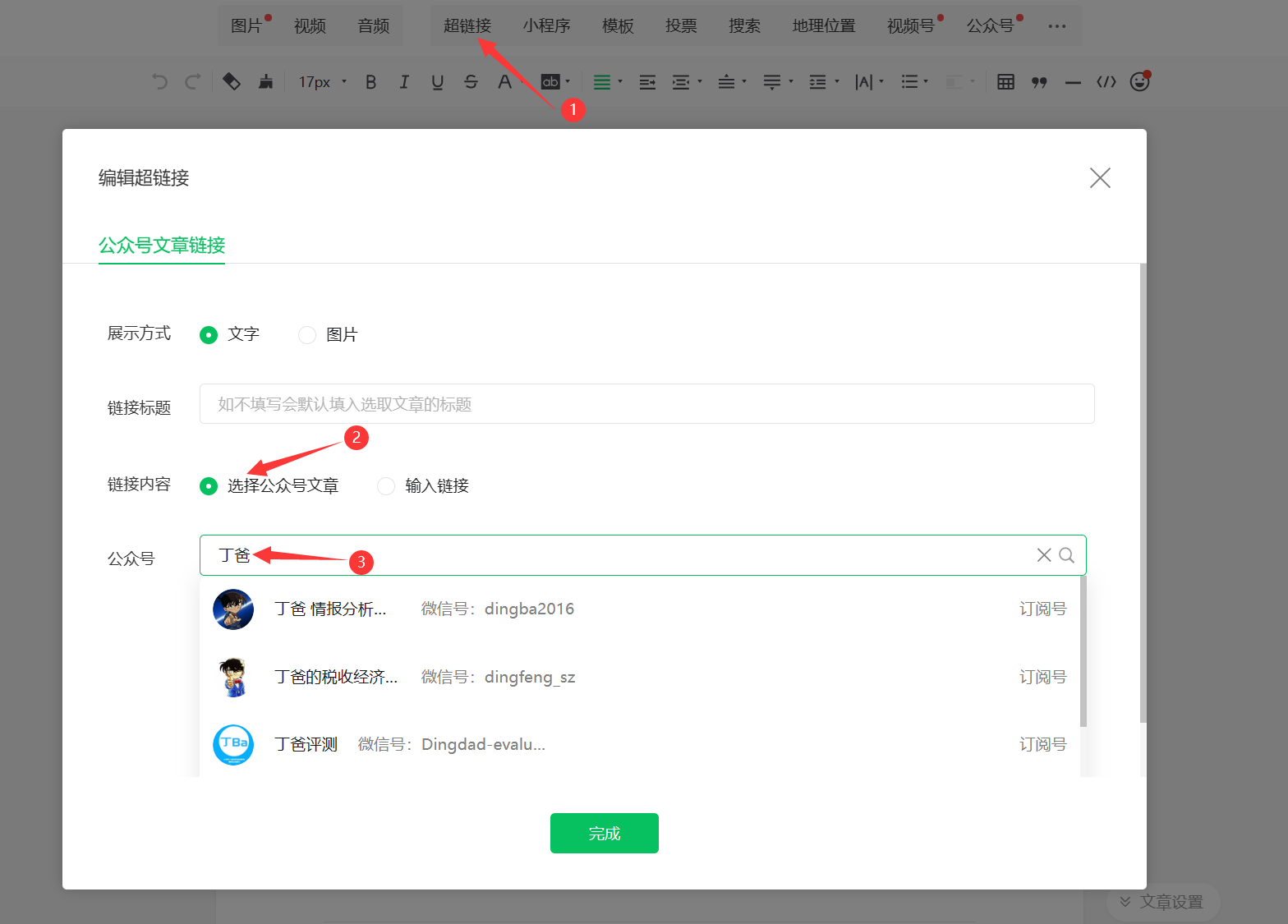
登录微信公众平台,新建文章,点击超链接。此时打开浏览器的检查模式,选择网络(Network),然后在窗口中选择你要爬取的公众号。
获取fakeid和token

这时我们可以看到,网络中出现了一个“appmsg”开头的内容,这就是我们需要的目标。将它的请求URL记录在下面(*隐去了部分内容):
1
| https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin=0&count=5&fakeid=MzI2********Mw==&type=9&query=&token=465***914lang=zh_CN&f=json&ajax=1
|
该链接分为三部分:
https://mp.weixin.qq.com/cgi-bin/appmsg 请求的基础部分?action=list_ex 常用于动态网站,实现不同的参数值而生成不同的页面或者返回不同的结果&begin=0&count=5&fakeid=MzI2MTE0NTE3Mw==&type=9&query=&token=465219914&lang=zh_CN&f=json&ajax=1 设置各种参数,我们需要的就是用到这里的fakeid=MzI2********Mw==以及token=465***914
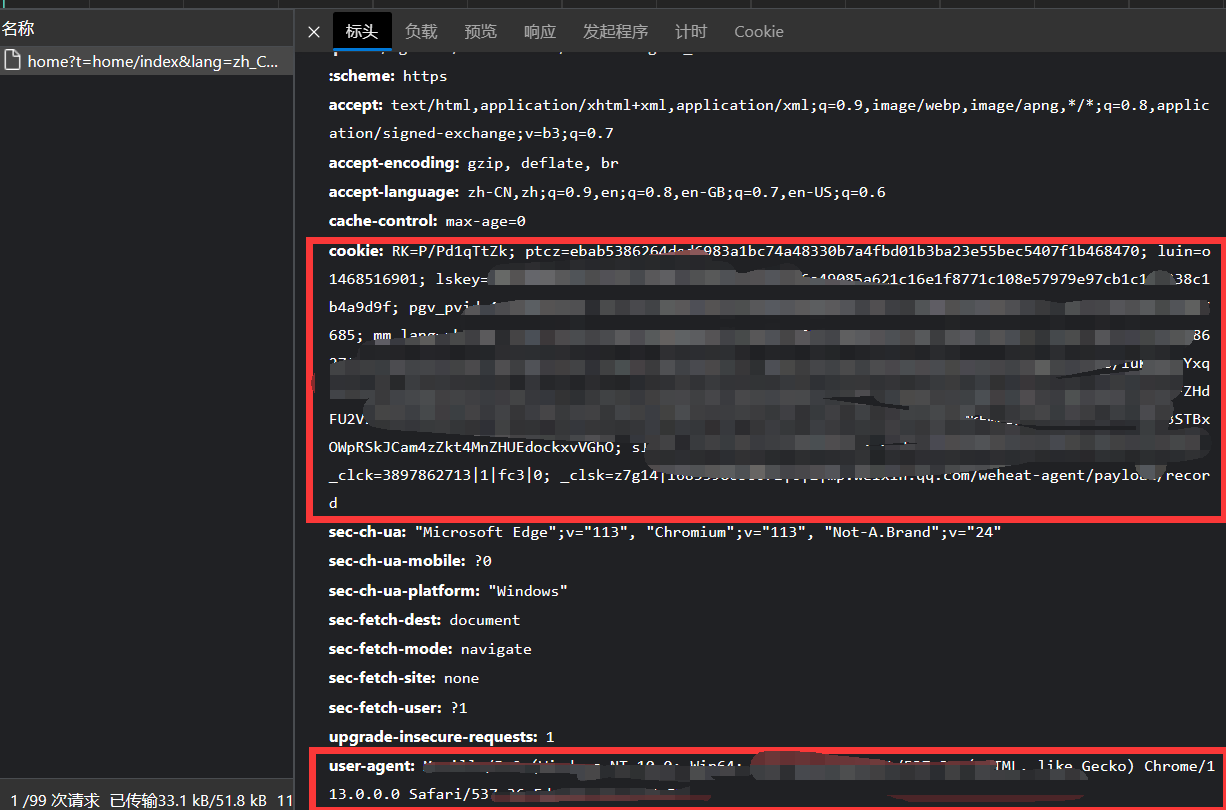
获取浏览器Cookie和User-Agent
在python运行时,我们需要它能以登录的状态去访问该URL。因此需要找到我们浏览器保存的Cookie和User-Agent:
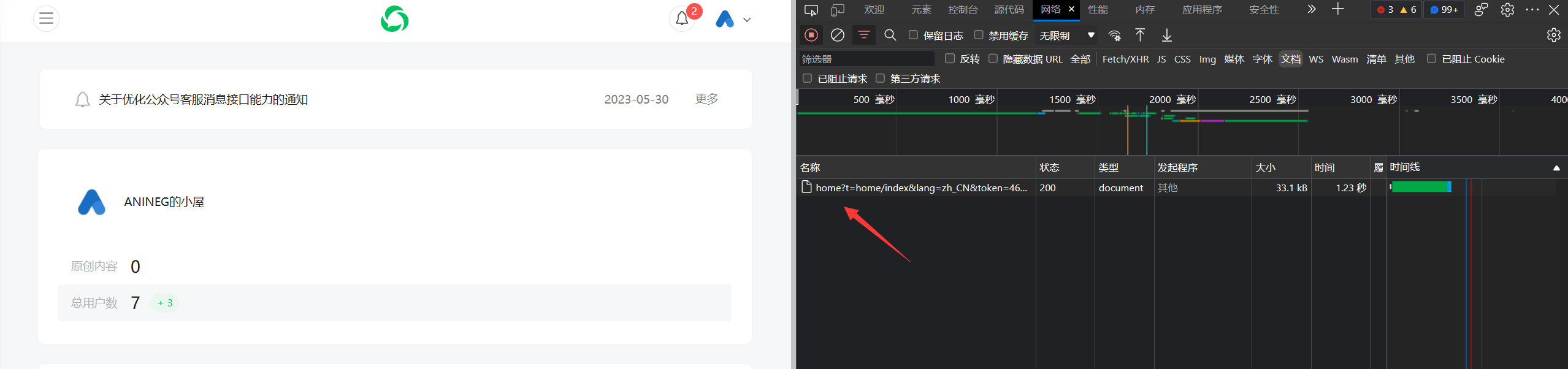
开浏览器的检查模式,选择文档(Document)。此时刷新网页,就可以看到一个“home”开头的内容:
从这里我们可以获得Cookie和User-Agent参数。
保存为yaml文件方便加载
将上述四个参数保存至一个wechat.yaml文件中,方便后面在python中加载。
文件内容:
1
2
3
4
| cookie : RK=P/Pd1qTtZk; ptcz......
user_agent : Mozilla/5.0......
fakeid : MzI2.......
token : 2023483153......
|
URL爬取
这部分主要参考了@Author:YuFanWenShu的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
| import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
app_msg_list = []
with open("app_msg_list.csv", "w", encoding='utf-8') as file:
file.write("文章标识符aid,标题title,链接url,时间time\n")
page = 0
while True:
begin = page * 5
params["begin"] = str(begin)
time.sleep(random.randint(1, 10))
resp = requests.get(url, headers=headers, params=params, verify=False)
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
time.sleep(3600)
continue
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
msg = resp.json()
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
with open("app_msg_list.csv", "a", encoding='utf-8') as f:
f.write(info + '\n')
print(f"第{page}页爬取成功\n")
print("\n".join(info.split(",")))
print("\n\n---------------------------------------------------------------------------------\n")
page += 1
|
经测试,每爬取大约200篇文章会遇到流量限制,此时需要等待一小时左右。一个账号一天最多只能爬取1000篇左右,我在这里测试的时候,是在大约1200篇的时候停下了,可能需要一天甚至更长的时间才能继续…….
将爬取的文章批量下载至本地(待改进)
使用pdfkit将文章转为PDF,可能需要安装:
1
2
3
| pip install pdfkit
pip install bs4
pip install html5lib
|
还需要安装一个工具:wkhtmltopdf下载链接
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| import csv
import re
import pdfkit
import requests
from bs4 import BeautifulSoup
options = {
'page-size': 'A4',
'encoding': "UTF-8",
}
path_wkthmltopdf = r'C:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe'
config = pdfkit.configuration(wkhtmltopdf=path_wkthmltopdf)
def validate_title(title):
rstr = r"[\/\\\:\*\?\"\<\>\|]"
new_title = re.sub(rstr, "_", title)
new_title = new_title.replace(':', ' _')
new_title = new_title.replace('?', '_')
return new_title
with open("D:\\turn-to-pdf\\app_msg_list.csv", 'r', encoding='utf-8') as f:
reader = csv.reader(f)
i = 1
for row in reader:
aid, title, url, time = row
if url.find('mp.weixin.qq.com') > 0:
res = requests.get(url)
if '此内容发送失败无法查看' in res.text:
continue
html = res.text.replace("data-src", "src").replace('style="visibility: hidden;"', "")
soup = BeautifulSoup(html, features="html5lib")
html = soup.select('div#img-content')[0]
html = str(html).replace("font-family: 仿宋;", "")
output = title + '.pdf'
pdfkit.from_string(str(html), output, configuration=config, options=options)
print(f"{i}:{title} 已完成")
i += 1
else:
print(f"Skipping {url} because it's not from WeChat.")
|
这一步有很多奇怪的问题,比如如果原文中有仿宋字体的话,在转成PDF后全部都不能正常显示。于是在转为PDF之前将HTML中的所有仿宋全部替换为默认字体。
这一部分还有诸多问题没有解决,但目前小部分的转换应该没有太大问题。偶尔还会遇到一些报错,暂时也还没有解决。如果各位大佬有办法,欢迎在评论区留言!
参考文章: